Prioritizing tasks in a Feature
Steve "ardalis" Smith recently posted this poll on Twitter:
You have a feature to implement. It includes 6 tasks. 3 of them you've done before many times; 2 you have other code that does something similar; 1 is totally new and will require research (and might not work at all).
— Steve "ardalis" Smith (@ardalis) October 22, 2020
Where do you start? RT for reach.
For me the answer was unknown task first — I din't even have to think about it. I was and still am 100% sure that this is how I'd always do it. Thinking about this through the week made me realize just how important the question was.
This post is me trying to understand where my intuition came from.
Starting with the Big Picture
When building a feature, I always take a top down approach. Understand why we're building it, how it fits into the product, how it'll impact the end user of the feature, etc. and then zoom into the feature's specifics.
If implementing our feature includes 6 tasks, those tasks are still part of one single feature, and it helps to always remember that.
The first thing I noticed in Ardalis' question was how he noted that the unknown might not even work. Which means we're looking at a possibility of a failure. Since the goal is to build a feature — and not perform 6 different tasks — failing on any task could mean we fail the feature.
Paths to success and failure
Once the big picture is well understood, it's time to picture a path to success. (I usually rely on past experience for this.) We do this because it's useful to know what it means to succeed or what it means to fail in the context of the feature.
Before we continue, let's look at what a feature building process might look like.
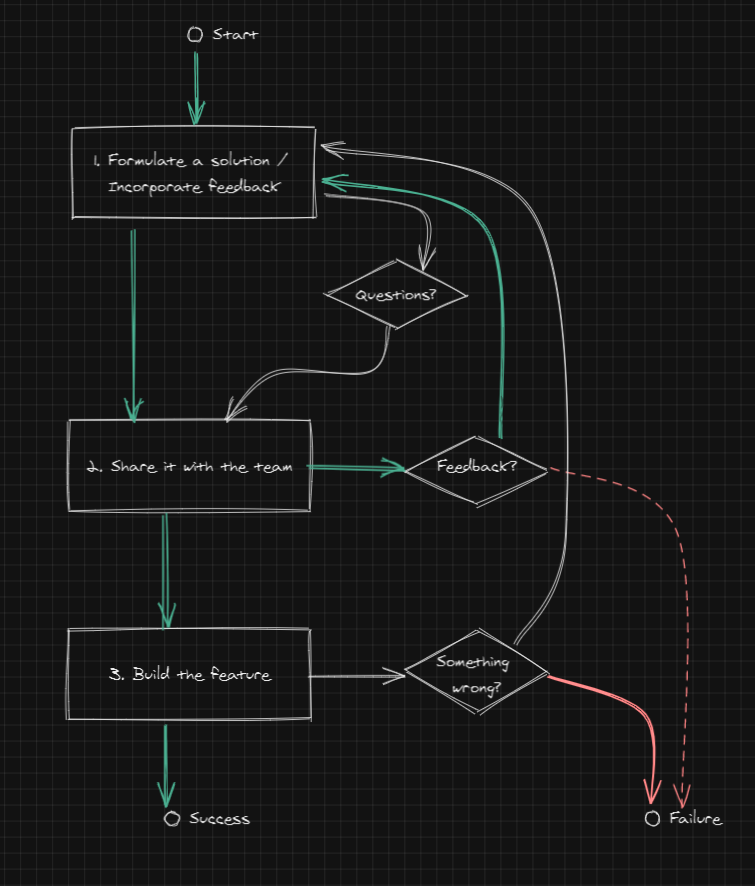
It should roughly consist of 3 steps:
- Come up with a solution to the problem.
- Share the solution (and/or questions) with the team. If they have any feedback go back to step 1 to incorporate it as needed.
- Now that the team have a rough idea of what you're trying to do (and everyone seem to be ok with how you're about to go about it), the feature can be built. If something goes wrong we stop, and go back to step 1 if needed.
At the end, the outcome is either a success, a partial success, or an outright failure. Failures can't always be avoided, but the damage can be limited by failing fast.
So if we need to picture a path to success, we'll need to BOTH understand technical aspects of the feature AND also recognize where our assumptions can fail us.
And so we need to know how to go about the unknown tasks, before we can see a clear path to success.
Starting with the unknown task
It's easy to test assumptions with known tasks — so easy that we might be doing it without even thinking about it — but it can be hard to test assumptions (or even be aware of them) with an unknown. Spending some time with the unknown goes a long way.
Starting with an unknown doesn't necessarily mean implementing it first. It could be just reading about it or writing a prototype, or asking others for ideas.
The key is to spend time with the unknown and get to know it to the point where we're comfortable committing to the feature. At the end of the day, agreeing to build a feature is also accepting a certain degree of responsibility.
Even if the feature doesn't end up getting released for whatever reason, there's still more value in detailed closed issues and/or prototype PRs with well written descriptions of the unknown, than in closed PRs that only have code that you know like the back of your hand.
Conclusion
It's good to have good defaults.
Starting with unknowns first is a good default.
My opinion, ofcourse :D